
デジタルツインライフサイクルの紹介
規制の厳しい産業環境でデジタルツインを製品化することは困難です。さまざまなデータレイクに接続し、データをクリーニングして人間や機械で使用できるようにすることから、主要なモデルアウトプットを視覚化、モデル化、さまざまな利害関係者にエクスポートすることまで、デジタルツインテクノロジーを効果的に活用するために組織が適切に行わなければならないステップは十数あります。インダストリー4.0が目指す今日の時代では、多くの組織がデジタル化の道のりのさまざまな段階にあります。一方では、クラウドベースのデータレイクへのデータの分類と一元化に取り組んでいる企業もあれば、さらに進んで、自社の資産や関連プロセスを表すための高度なモデルをすでに多数構築している企業もあります。
デジタルツインのプロダクション化の中核は、エンジニアリング、規制、サイバーセキュリティの厳しい要件を満たすために複数のチームが連携して取り組む対象分野の専門知識です。エンジニアリングの観点から見ると、デジタルツインは説明可能で、物理システムの物理学、生物学、化学に基づいている必要があります。規制の観点から見ると、監査を可能にするには、入念な記録管理が必要です (つまり、モデルがいつ構築されたか、どのデータがトレーニングに使用されたか、モデルの出力がどのように消費されたかなどを追跡すること)。最後に、サイバーセキュリティの観点から見ると、デジタルツインが制御システムやその他のミッションクリティカルなデータベースと直接的または間接的にどのように連携するかについて、IT部門が厳重な管理を要求することがよくあります。
デジタルツインのライフサイクルには多くの複雑な要素があるため、デジタルツインの出荷には、複数の専門分野にまたがるチーム間のコラボレーションと引き継ぎも必要です。多くの組織はエンジニアリング、データサイエンス、IT などのチームを設立していますが、必ずしもデジタルツインとライフサイクル管理を通じたデジタル化専用の作業ストリームがあるとは限りません。
この記事では、次の図に示す TwinOps ワークフローによるデジタルツインライフサイクルの概要について説明します。TwinOpsは、デジタルツインを設計から製造まで進め、運用後にそれらを維持および監視するためのインフラストラクチャを提供するライフサイクルに重点を置いています。
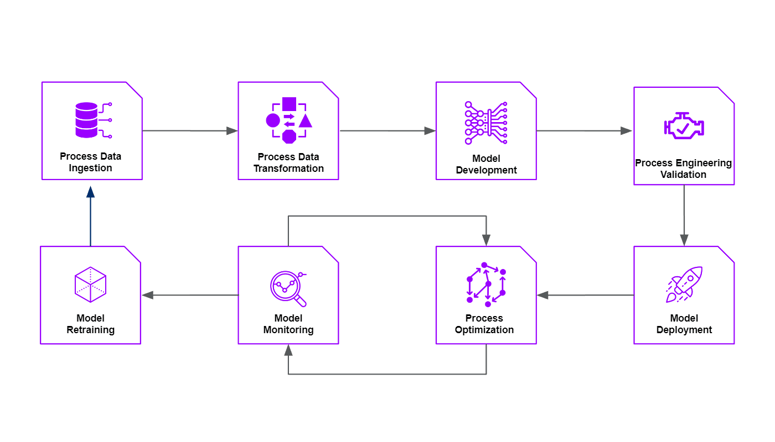
ステップ 1-2: プロセスデータの取り込みと変換
何よりもまず、データをさまざまな異なるソース (または理想的には一元化されたデータレイク) から取り込み、統一された使いやすい形式に変換する必要があります。変換には、データの再形成、さまざまなタイムスケールや解像度に合わせた測定値の調整、センサーノイズや誤った測定値のフィルタリングなどが含まれます。
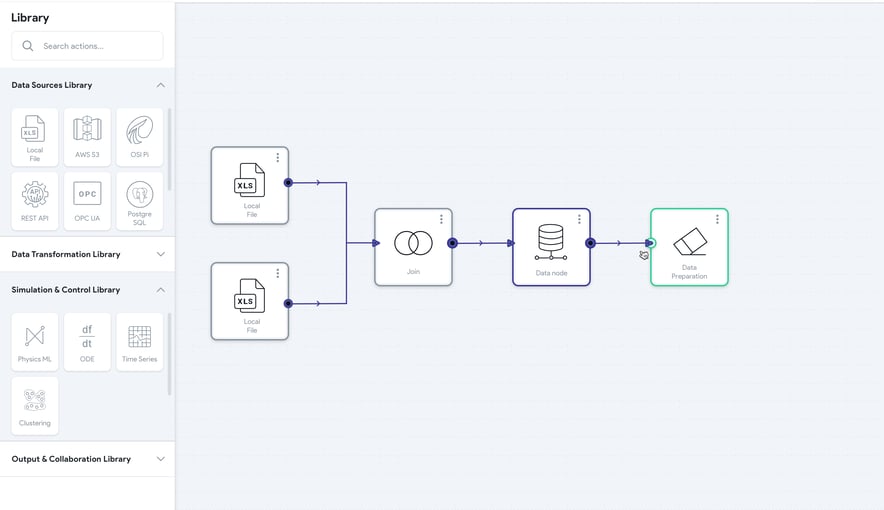
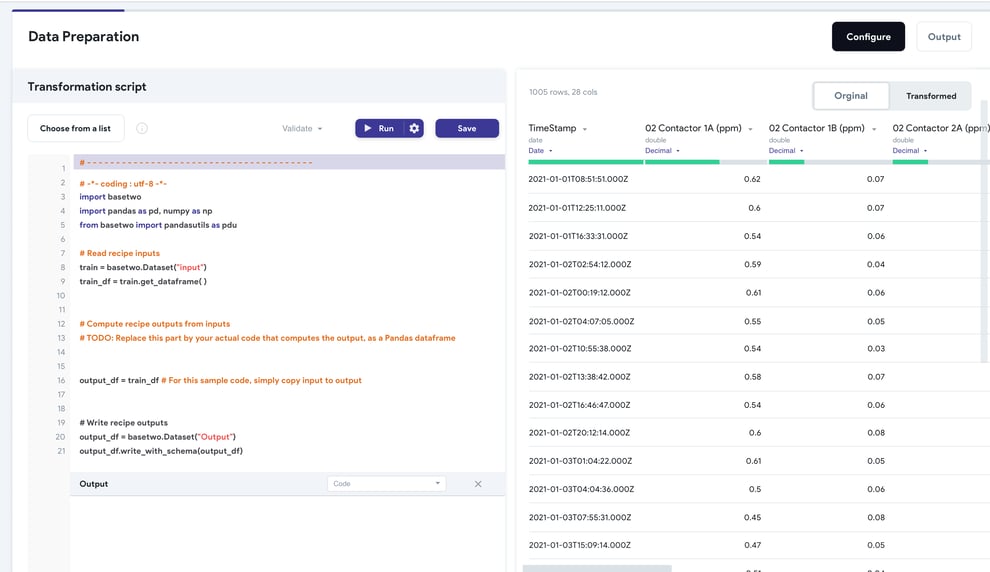
十分に開発されたTwinOpsワークフローにより、ユーザーは堅牢なデータパイプラインを構築してデータ処理を自動化し、データサイロを解消することができます。パイプラインが最新の状態であることを確認するために、定期的に最新のデータセットを取得するようにスケジュールを設定しておけば、この情報を活用するモデルの妥当性と価値を維持できます。上級ユーザーの場合、オープンソースライブラリを使用して Python、R、SQL などの広く使用されている言語のデータ変換スクリプトにアクセスできるようにすることで、組織が利用できるデータ変換機能を大幅に深めることができます (下図を参照)。
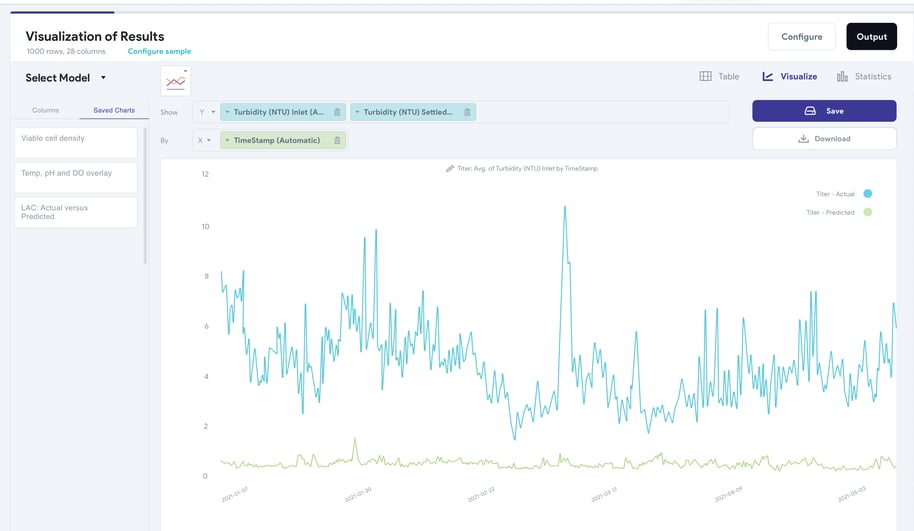
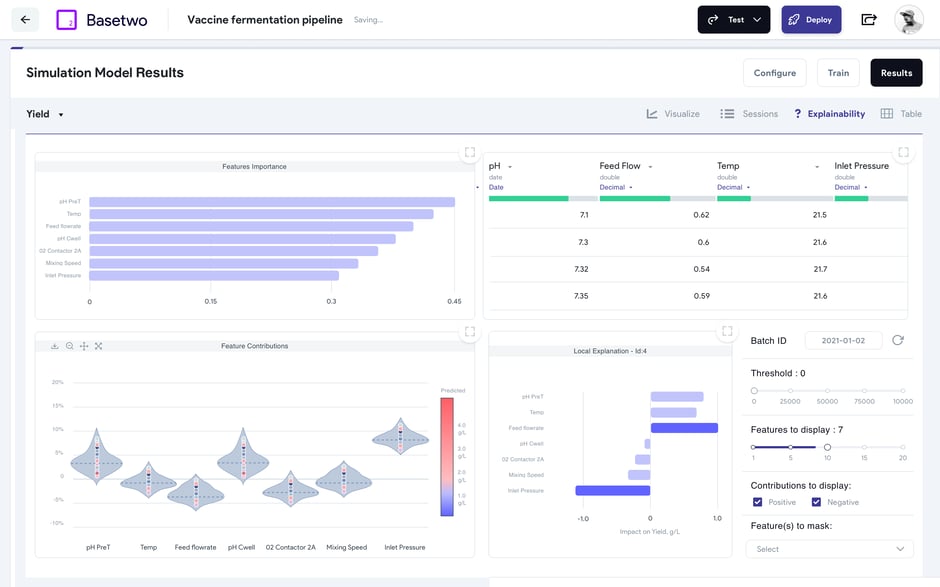
さらに、複数のバッチ、パラメーター、タイムポイントにわたるプロセスデータを時系列プロットで視覚化することは、対象分野の専門家がクエリされたプロセスを理解し、プロセスの相関関係、明確なプロセスの傾向、挙動を視覚的に特定できるようにするために不可欠です。また、欠陥のあるセンサー測定値に注意を向けることもできます。後者は、発生したプロセス障害やドリフトに関する洞察をオペレーターに提供できるため、本質的に価値があります。
ステップ 3: モデル開発
データが調整され、視覚的に評価され、使用可能な形式に解析されると、プロセスモデラーはエンジニアリングの知識や科学分野の専門知識を取り入れて、特徴付けたいプロセスの堅牢で説明可能なモデルを構築することがよくあります。もちろん、これはモデルトレーニング (つまりパラメータ推定) と検証を伴う反復的なプロセスであり、モデル推定が定義された設計空間や過去の実験やデータセットと一致することを確認するための検証が必要です。
これらのモデルは、現実世界のシステムデータの入力と出力の間の動作を理解するデータ駆動型モデルでも、システムを支配する一連の微分方程式を通じて対象のプロセスを記述するメカニスティックモデルでも、定義された機械的関係に従ってモデルの学習が制約されるハイブリッドモデルでもかまいません。基本的に、各アプローチの利点を組み合わせることができるデータ駆動型モデルとメカニズムモデルの相乗的アプローチを表しています。

ハイブリッドデジタルツインを構築するために、プロセスモデラーやエンジニアは、過去の運用データが入手できるプラントユニットの操作から始めて、それを物理情報に基づいたニューラルネットワークまたはPINNを介してフィードする場合があります。この PINN は、エンジニアが提供する基礎となる物理または化学に基づいて作成されるため、モデリングチームや他のチームは、データをプロセス機器の実際のドメイン知識と効果的に組み合わせることができ、モデルの精度と効率を高めることができます。このモデルのもう1つの利点は、透明性が高く、説明しやすいことです。従来のブラックボックスシステムの代わりに、エンジニアは内部を調べてプロセスパラメータの関係を調査し、モデルが推奨を行っている理由を知ることができるため、これらのモデルへの信頼性が大幅に向上します。
ハイブリッドモデリングの詳細については、ブログ投稿をご覧ください。 ここに。
確立されたTwinOpsプラットフォームには、一般的なユニット操作や上流または下流プロセス用のモデルテンプレートの既存のライブラリがあり、ユーザーがそれらを利用、構築、反復、デプロイできる場合があります。その他の機能としては、ユーザーが作成したカスタムモデルを保存して共有し、組織全体にわたる部門間のコラボレーションを促進する機能などがあります。
ステップ 4 ~ 6: モデルの検証、展開、およびプロセスの最適化
モデルに関する検証作業には、プロセスモデラー、データサイエンティスト、プロセスエンジニアなど、さまざまなエンドユーザーの対象分野の専門知識が必要になる場合があります。これらのチームは、研究対象のシステムのダイナミクスを表すモデルの妥当性を検証するために、科学文献の情報源、業界標準、ガイドライン、過去のプロセス情報、その他の外部の協力者に頼る場合があります。検証は反復の多いプロセスでもあり、モデルはある環境では有効でも、プロセスやプロセスに投入される原材料が変更された場合などには再検証が必要になることがあります。
ユーザーがデジタルツインモデルの検証に成功したら、モデルを実稼働環境に展開して実行と推論を行う必要があります。これには、運用データのライブストリームや最新のラボ測定データを取り込むことができる API エンドポイントにデプロイすることが必要になる場合があります。処理 (上記) 後、このデータは検証済みのモデルに入力され、プロセスを視覚化、分析、理解できるようになります。導入には、オペレーター、プロセスエンジニア、その他のエンドユーザーがプラントフロアレベルの推奨事項を利用してプロセス条件を変更/最適化すると同時に、プロセスモデラーやデータサイエンティストにフィードバックを送り、必要に応じて運用上のニーズに合わせてモデルをさらに修正します。
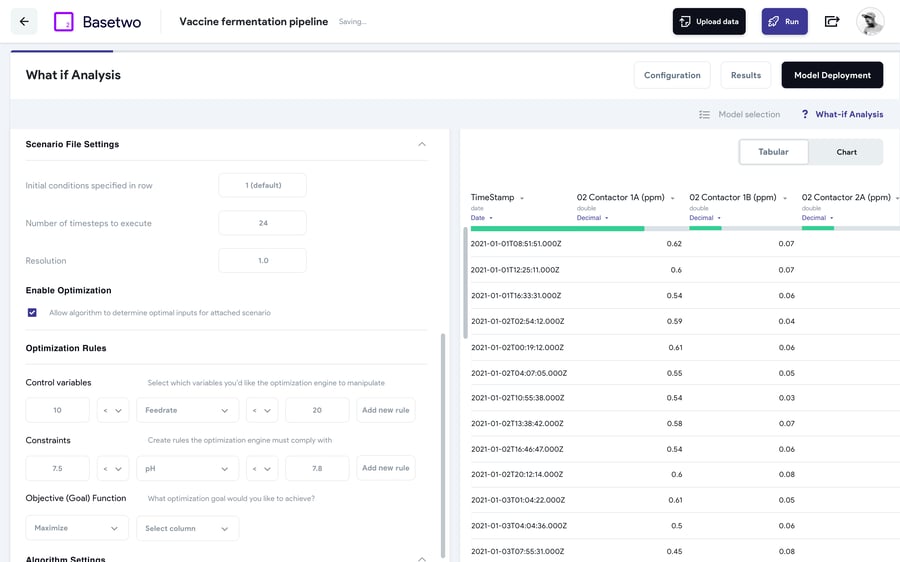
通常、モデルはプロセス最適化のユースケース(つまり、特定のプロセスまたは機器に最適な制御セットポイントの決定)に使用されます。これには、デジタルモデルを多変量最適化アルゴリズムと並行して大規模に実行することが含まれます。最適化について詳しくは、ブログ記事をご覧ください。 ここに。TwinOps プラットフォームを導入すると、ユーザーはどのパラメーターが KPI に影響を与えているかを調べて、プロセスの理解を継続的に向上させることができます。
導入モデルの最終的な目標は、貴重な製造リソースを消費することなく、デジタルツインを活用して実際のプロセス条件を予測できるデジタル実験またはインシリコ実験を可能にする機能を提供することです。その一例が、仮想「what-if」実験です。この実験では、ユーザーがモデルにクエリを実行して、オフライン環境の新しい条件下でのプロセスダイナミクスを予測します。これをオンラインシステムにも拡張できます。オンラインシステムでは、モデルが進化するにつれてプロセスの品質に関する予測と決定をリアルタイムで行うことができるため、メーカーは継続的にプロセスを調整したり、バッチの不具合を回避したりできます。
ステップ 7-8: モデルの監視と再トレーニング
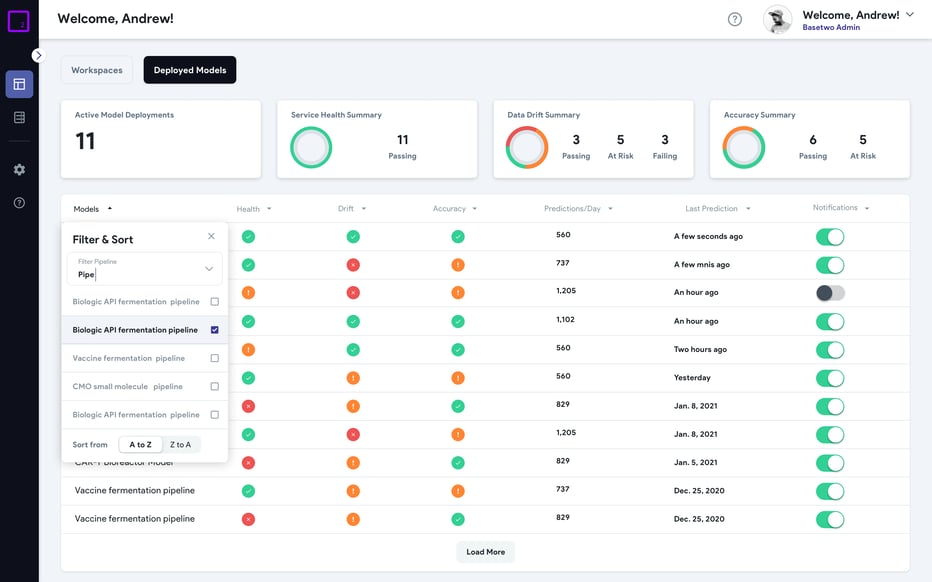
いったん導入されたデジタルツインモデルは、運用条件や原材料が変化しても精度が十分に維持されるように、継続的に監視する必要があります。モデルの品質に変化が見られたら、ユーザーはモデルをオフラインにして再トレーニングを行ってから、本番環境に再デプロイすることもできます。この再トレーニングには、最新の履歴データセットの取り込みや、データ処理またはモデリングのアプローチの変更が含まれる場合があります。
理想的には、生産環境でモデルの監視、再トレーニング、更新を行う際に、ユーザーがモデルのランタイム、アクティビティ、バージョン管理の履歴にアクセスして、さまざまな優良製造基準(GMP)やその他の規制要件を満たす必要があります。さらに、スーパーバイザーやマネージャーに、デプロイされたモデルを現在活用しているサイトやチームを可視化し、関連するモデルSOPやその他の文書を添付することで、モデルの採用が大幅に改善され、チームが古いモデルを使用していないことを確認するための可視性が大幅に向上します。
次は何?
全体として、TwinOpsは、データの取り込みからモデルの展開と監視まで、デジタルツインのライフサイクル全体を網羅しています。Basetwoは、組織がデジタル化のどの段階にいるかにかかわらず、製造環境におけるデータ活用方法に革命をもたらすエンドツーエンドの TwinOps プラットフォームを提供します。詳細を知りたい場合は、当社のユースケースとホワイトペーパーをぜひご覧ください。 リソースページ。


