
Introduction to the Digital Twin Lifecycle
Productionizing digital twins in an industrial, regulated environment is challenging. From connecting to a variety of data lakes and cleaning data to make it human or machine useable, all the way to visualization, modeling, and exporting of key model outputs to various stakeholders, there are a dozen different steps organizations need to get right to effectively benefit from digital twin technologies. In today’s age of aspirational Industry 4.0, many organizations are at various stages of their digitalization journeys. On one end, some may be working at sorting and centralizing their data onto cloud-based data lakes, while others may be further along and already have numerous sophisticated models built to represent their assets and related processes.
The core of productionizing digital twins is subject matter expertise across multiple teams to work synchronously to meet stringent engineering, regulatory, and cybersecurity requirements. From an engineering perspective, digital twins need to be explainable and grounded in the physical system’s physics, biology, and/or chemistry. From a regulatory perspective, diligent record-keeping is required for auditability (i.e., tracing when models were built, what data was used for training, how model outputs were consumed, etc). Lastly, from a cybersecurity perspective, IT departments often require significant controls on how digital twins may interface directly or indirectly with control systems and/or other mission-critical databases.
Shipping digital twins also require collaboration and hand-offs across multidisciplinary teams, given the many complex components of the digital twin lifecycle. While many organizations may have established engineering, data science, IT, and other teams, they may not necessarily have a dedicated work stream to digitalization through digital twins and lifecycle management.
This article provides an overview of the digital twin lifecycle through a TwinOps workflow shown in the figure below. TwinOps is focused on the lifecycle of taking digital twins from design to production, and then providing the infrastructure to maintain and monitor them once operationalized.
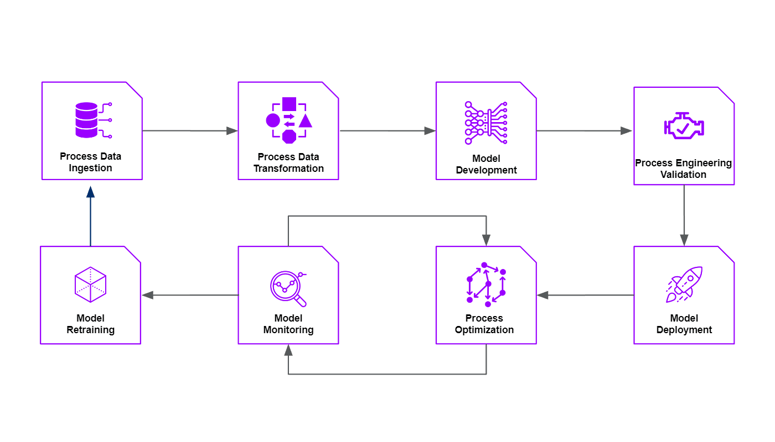
Steps 1-2: Process Data Ingestion and Transformation
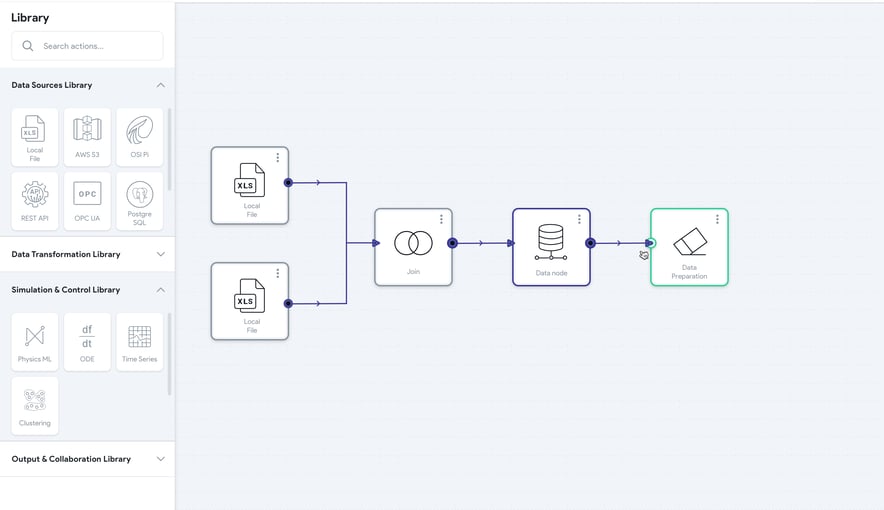
First and foremost, data needs to be ingested from a variety of disparate sources (or ideally a centralized data lake) and then transformed into a unified, usable format. Transformations could include reshaping data, aligning measurements with various timescales and resolutions, and filtering sensor noise or erroneous measurements.
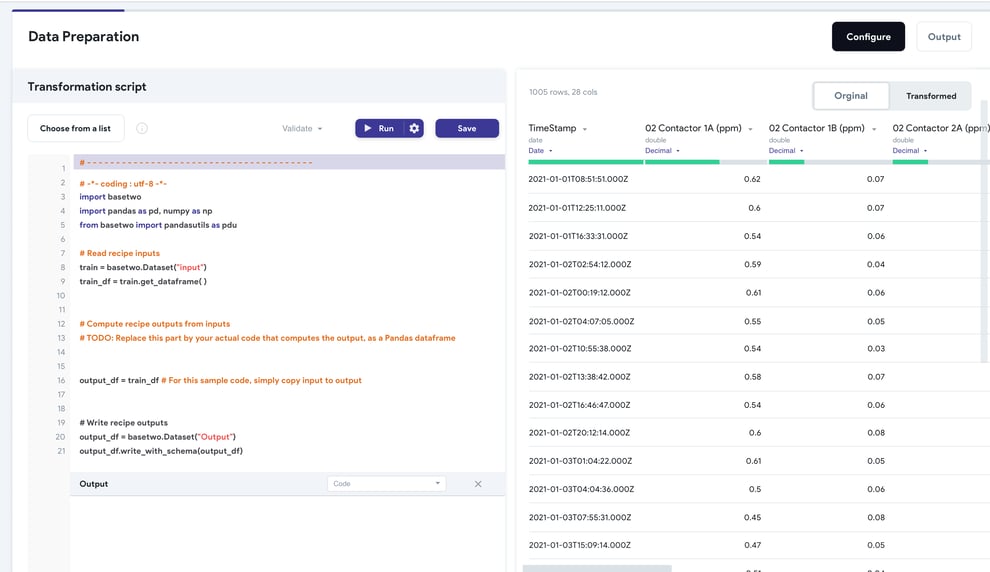
A well-developed TwinOps workflow will allow users to build robust data pipelines to automate data processing and break down data silos. Regular scheduling to pull the latest datasets available to ensure pipelines are up-to-date can ensure models leveraging this information stay relevant and valuable. For advanced users, providing access to data transformation scripts in a widely used language like Python, R, or SQL using open-source libraries can massively increase the depth of data transformation capabilities available to an organization (see figure below).
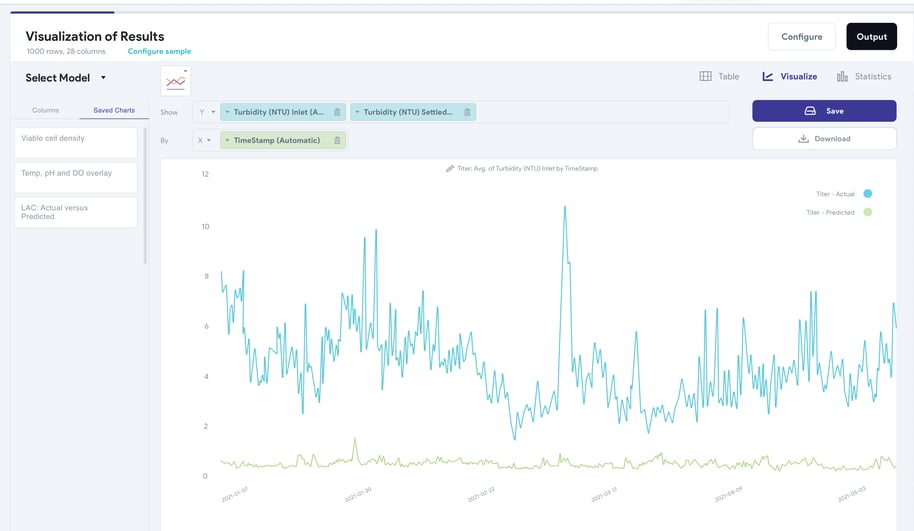
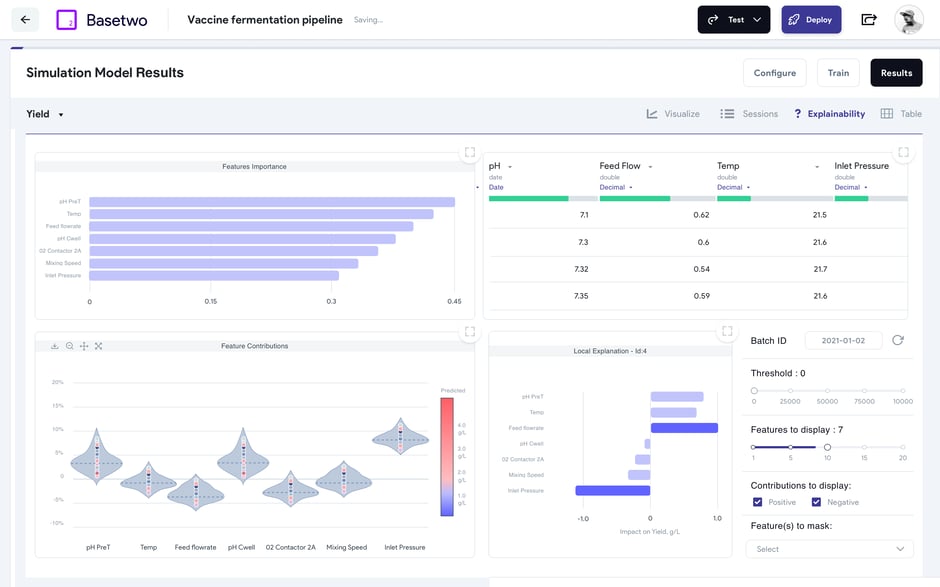
Beyond this, visualizing process data across multiple batches, parameters, and timepoints in a time-series plot is crucial to allowing subject matter experts to understand the queried process and visually identify process correlations, distinct process trends, and behaviours, or even draw attention to faulty sensor measurements, the latter of which can be inherently valuable by providing operators with insight into any process failures or drifts that have occurred.
Step 3: Model Development
Once the data has been reconciled, visually assessed, and parsed into a useable format, process modelers will often incorporate engineering knowledge or scientific domain expertise to build robust, explainable models of the process they wish to characterize. Of course, this is an iterative process involving model training (i.e. parameter estimation) and validation to ensure model estimates align with the defined design space or historical experiments and datasets.
These models can be data-driven, which understands the behavior between inputs and outputs of real-world systems data, or mechanistic, which describes the process of interest through a set of differential equations governing the system, or even hybrid, where the learning of the model is constrained according to defined mechanistic relationships, essentially representing a synergistic approach of the data-driven and mechanistic models that can combine the benefits of each approach.

To build a hybrid digital twin, a process modeler or engineer may start with a plant unit operation from which historical operations data is available, and then you feed that through a physics-informed neural network or PINN. This PINN is guided by the underlying physics or chemistry provided by engineers, effectively allowing modeling and other teams to combine data with actual domain knowledge of your process equipment, enhancing the accuracy and efficiency of these models. Another benefit of this model is that they are transparent or explainable - instead of traditional black box systems, they allow engineers to look under the hood and investigate process parameter relationships to learn why a model is making the recommendations it does, greatly improving trust in these models.
For more information on hybrid modeling, check out our blog post here.
An established TwinOps platform may have existing libraries of model templates for common unit operations and upstream or downstream processes, which users can utilize, build on, iterate on and deploy. Other capabilities may include the ability to save and share custom models built by users to facilitate cross-functional collaboration across the organization.
Steps 4-6: Model Validation, Deployment, and Process Optimization
Validation activities surrounding models may require subject matter expertise from a variety of end users, including process modelers, data scientists, and process engineers. These teams may rely on scientific literature sources, industry standards, guidelines, historic process information, and other external collaborators to verify the validity of the models to represent the dynamics of the system being studied. Validation is also a highly iterative process, wherein models may be valid for one environment but may need to be re-validated if the process or raw materials fed into the process change, for example.
When the user has successfully validated a digital twin model, they then need to deploy the model to a production environment for execution and inferencing. This could involve deploying it to an API endpoint where a live stream of operational data or the latest batch of lab measurements could be fed into it. After processing (described above), this data will be fed into validated models to visualize, analyze and understand the process. The deployment will involve operators, process engineers, and other end users to make use of the recommendations on a plant floor level to change/optimize process conditions while giving feedback to process modelers and data scientists to further modify models as needed to fit operational needs.
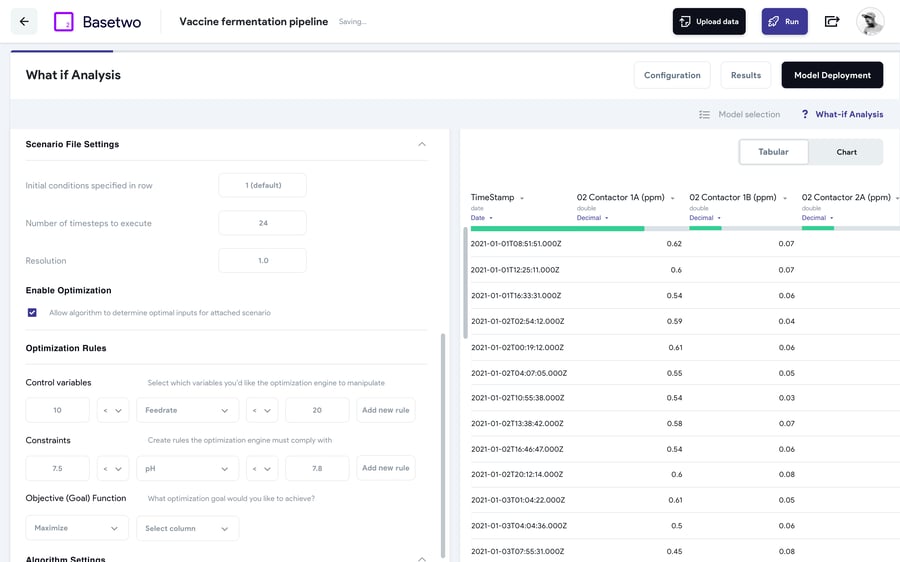
Typically, a model will be used for process optimization use cases (i.e. determining the optimal control setpoints for a given process or equipment). This involves executing the digital model in tandem with a multivariate optimization algorithm at scale. To learn more about optimization, check out our blog post here. Once deployed, a TwinOps platform will allow users can investigate what parameters are driving KPIs to continuously improve process understanding.
The ultimate goal of deployed models is to provide the ability to unlock digital or in silico experimentation, wherein the digital twin can be leveraged to predict real process conditions without consuming precious manufacturing resources. An example of this is virtual “what-if” experiments, where a user queries the model to predict process dynamics under novel conditions in an offline environment. This can be extended to an online system, where the model can make real-time predictions and decisions regarding the quality of a process as it evolves, allowing manufacturers to continuously tune processes or avoid batch failures.
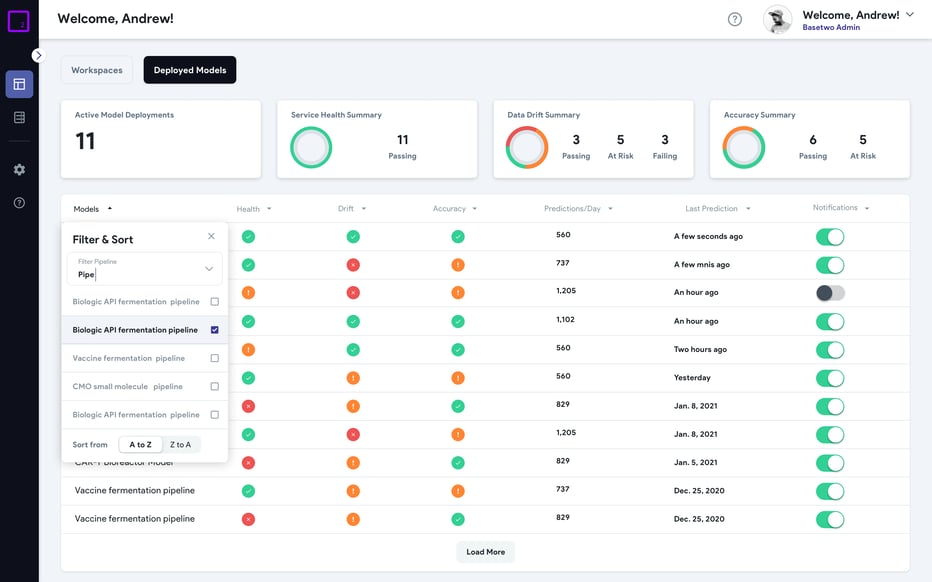
Steps 7-8: Model Monitoring & Retraining
Once in its deployed state, the digital twin model will require continuous monitoring to ensure its accuracy is sufficiently maintained in the face of changing operating conditions or raw materials. Once a drift in model quality is detected, the user may choose to take the model offline for retraining before redeploying it back to production. This retraining may involve ingesting the latest historical dataset or a change to either the data processing or modeling approach.
Ideally, users should have access to a history of model runtime, activity, and version control to meet a variety of good manufacturing practice (GMP) or other regulatory requirements as models are monitoring, retraining, and updated in a production environment. In addition, providing supervisors and managers visibility into which sites and teams are currently leveraging deployed models and attach associated model SOPs and other documentation can significantly improve both model adoption and improve visibility to ensure teams are not using outdated models.
What’s next?
Overall, TwinOps encompasses the entirety of the digital twin lifecycle, from data ingestion to model deployment and monitoring. Regardless of where an organization may be in its digitalization journey, Basetwo offers an end-to-end TwinOps platform to revolutionize how data is being leveraged in manufacturing environments. If you’re interested in learning more, feel free to check out our use cases and white papers on our resource page.


