
はじめに
物理情報に基づく機械学習(PIML)では、既存の専門知識(物理学、化学、生物学など)を機械学習(ML)に組み込んで、動的な産業システムを効果的にモデル化します。これらの動的システムは、高いセンサーノイズやまばらな測定値などの課題に直面しますが、多くの場合、ある程度の基礎的な科学/工学的知識が特徴です。
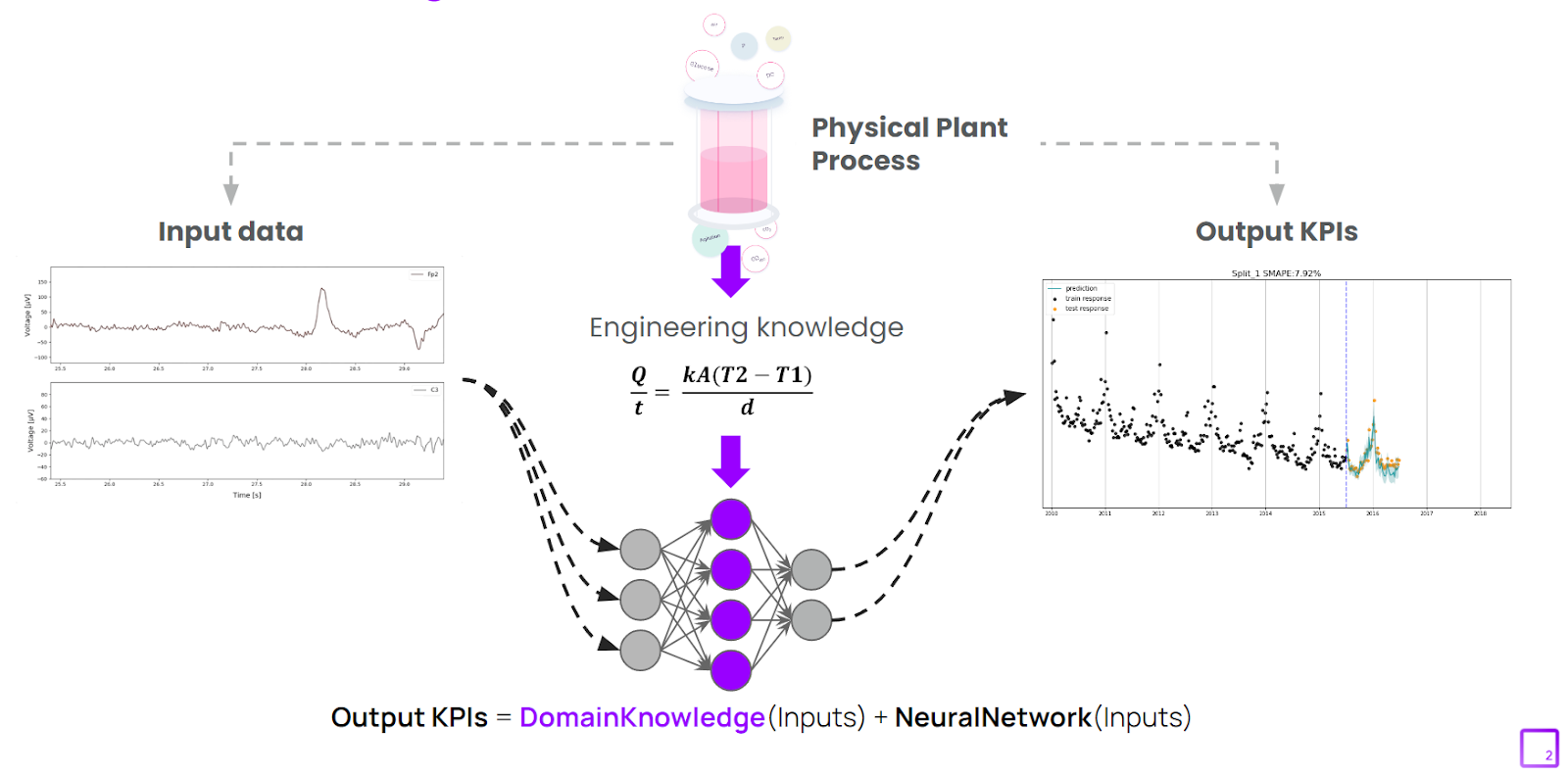
言い換えれば、物理学は既知のシステムダイナミクスを確立し、MLは確立された物理モデル/知識のギャップを埋めます。物理ベースのモデルは、質量収支規則 (つまり、入力の合計が出力の合計と等しい) のように単純な場合もあれば、システムの進化を説明する偏微分方程式の完全なセット (クロマトグラフィーカラム上のタンパク質結合) の場合もあります。
機械学習にドメイン知識を組み込む方法
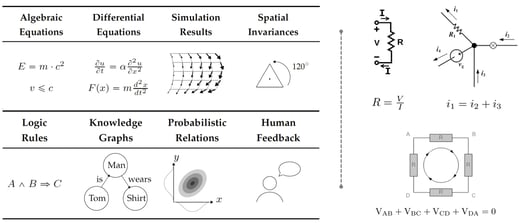
ドメイン知識を機械学習に組み込む一般的な方法は3つあり、これについては後のセクション [1] で説明します。
- データへの観測バイアスの導入
- モデル構造への誘導バイアスの導入
- モデルのトレーニング方法への学習バイアスの導入
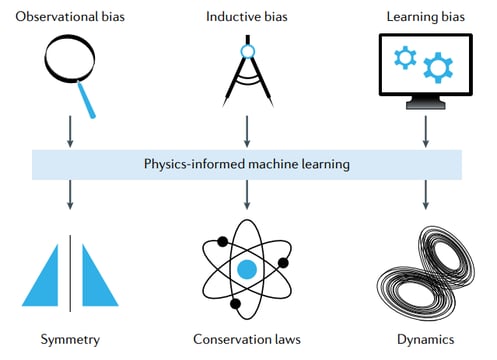
1。観測バイアスの紹介
観測バイアスは、基礎となる物理現象を具体化するデータから直接導入することも、データのクリーニングや処理によって導入することもできます。基本的に、データサイエンティストまたはエンジニアは、粒子物理システムを最もよく表すサブセットだけを抽出して、プロセスデータをフィルタリングします。
これは、大量のデータを扱う場合に ML にバイアスを導入する最も簡単な方法です。このプロセスは通常、基礎となるプロセスの特定の対称性とダイナミクスを考慮した予測を生成するために必要です。
この方法は、大量のデータの前処理と操作が必要であり、産業環境では必ずしも実行できないため、産業用デジタルツインアプリケーションにとって非常に困難な場合があります。
2。誘導バイアスの紹介
帰納的バイアスは、機械学習モデルアーキテクチャに合わせた介入によって組み込むことができる事前仮定に対応します。これにより、求められる予測が、通常は特定の数学的制約の形で表現される一連の物理法則を暗黙的に満たすことが保証されます。基本的に、プロセスの基礎となる物理学の期待に合うように ML モデルのアーキテクチャを変更することができます。
このようなアプローチは、その有効性は高いものの、現在のところ、比較的単純で明確に定義された物理群または対称群を特徴とするタスクに限定されており、多くの場合、重要な主題に関する専門知識と精巧な実装が必要です [1]。
さらに、多くの物理システムを特徴付ける基礎となる不変性は、よく理解されていないか、ニューラルアーキテクチャに暗黙的にエンコードするのが難しいことが多いため、それらをより複雑なタスクに拡張することは困難です。特に、ニューラルネットワークを使用して微分方程式を解く場合は、必要な初期条件を正確に満たすようにアーキテクチャを変更することができます [1]。さらに、PDE ソリューションの一部の特徴があらかじめわかっている場合は、それらをネットワークアーキテクチャにエンコードすることもできます [1]。
3。ラーニング・バイアスの紹介
最新の実装では、ドメイン知識を暗黙的に適用する特殊なアーキテクチャを設計する代わりに、従来のニューラルネットワークの損失関数を適切にペナルティとして課すことで、このような制約をソフトな方法で課すことを目指しています [1]。
このアプローチは、マルチタスク学習の特定のユースケースと見なすことができます。このアプローチでは、学習アルゴリズムが観測データに適合するように同時に制約され、特定の物理的制約をほぼ満たす予測が生成されます。これにより、代数方程式や微分方程式の形で表現できる幅広い種類の領域駆動型バイアスを導入するための非常に柔軟なプラットフォームとなります。
学習バイアスアプローチの代表的な例には、物理情報に基づくニューラルネットワーク(PINN)とそのバリアントが含まれます。
物理情報に基づくニューラルネットワーク (PINN)
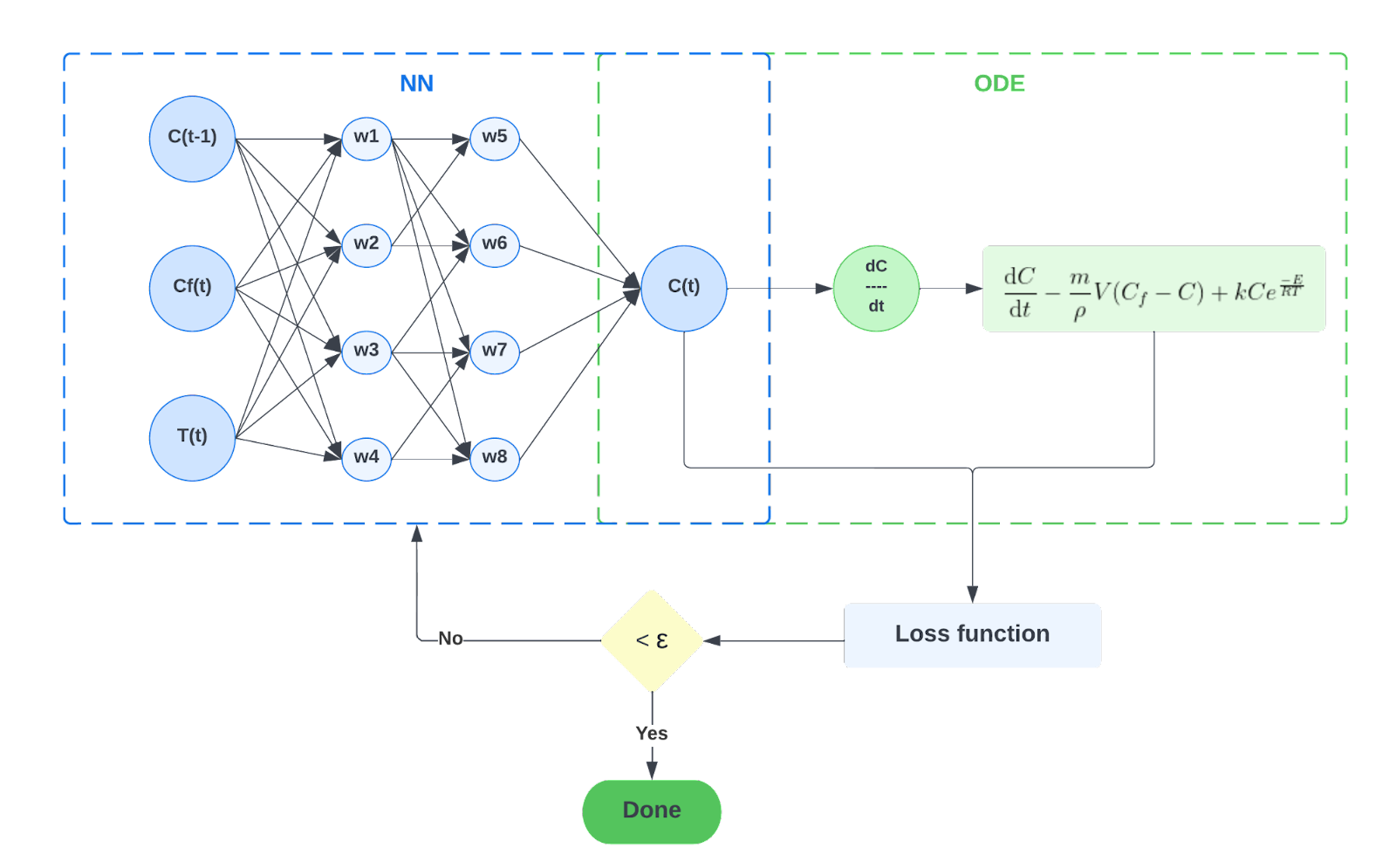
物理情報に基づくニューラルネットワーク(PINN)は、現実世界の測定値と機構モデル(常微分方程式または偏微分方程式(ODE/PDE))の両方からの情報を統合します。この積分は、自動微分を用いて常微分方程式と偏微分方程式をニューラルネットワークの損失関数に組み込むことで実現されます。
化学品製造用の完全攪拌型リアクター (CSTR) の例を使用して、フォワード問題を解決するためのPINNアルゴリズムを紹介します。
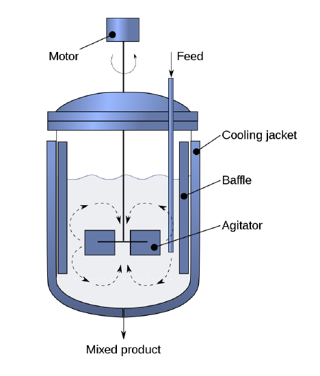
ここでは、CSTR内の電動攪拌機が容器内で完全に混合される環境を作り出すと仮定します。さらに、生成物の流れは原子炉の流体と同じ濃度と温度になると仮定します。反応化学を比較的単純にするために、ここでは一次反応速度論を仮定します。また、この分析ではエネルギーバランスも除外しました。
生成物濃度ストリームの質量バランスを単純にすると、次の常微分方程式 (ODE) が得られます。
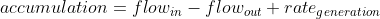
上記 ODE で使用される用語の概要を以下の表に示します。
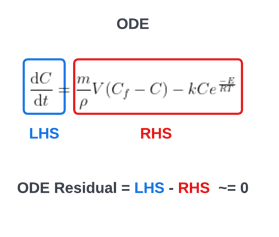
ODE の左辺から右辺を引くと、ODE の残差項または損失項を計算できます。一般的な機構モデルフィッティングの用途では、さまざまなモデルパラメータを実際のプラントの測定値にあてはめることで、このモデルをキャリブレーションすることを目指します。これには、以下の実際の測定値を代入することが含まれます。 Cf、 C そして T 履歴データから取得し、微分を計算します C ODEの残留/損失を最小限に抑えるためです。
ODE をニューラルネットワークのフレームワークに組み込むために、C のデータ損失の測定値に、前述の ODE の教師なし損失を付加します。
wデータ そして wオード は、2 つの損失条件間の相互作用のバランスを取るために使用される重みです。これらの重みはユーザーが定義することも自動的に調整することもでき、PINN のトレーニング性を向上させる上で重要な役割を果たします [1,7]。ネットワークの学習には、Adam や L-BFGS などの勾配ベースのオプティマイザーを使用して、損失がユーザー定義のしきい値 416よりも小さくなるまで損失を最小限に抑えます。
結論
物理情報に基づく機械学習(PIML)は、確立されたドメイン知識を機械学習に組み込んで、動的な産業システムを正確にモデル化するプロセスです。ML にドメイン知識を組み込む一般的な方法には、次の 3 つがあります。
- データへの観測バイアスの導入
- モデル構造への誘導バイアスの導入
- モデルのトレーニング方法への学習バイアスの導入
物理情報に基づくニューラルネットワーク (PINN) は、ODEをニューラルネットワークの損失関数に組み込むことで、プロセスデータとエンジニアリング知識の両方からの情報を統合する新しいアプローチです。PIMLは、ノイズの多い高次元のコンテキストでもデータと数学モデルをシームレスに統合します。物理モデルとデータをブレンドする自然な機能と、自動微分の使用により、PIMLはデジタルツインの新時代を実現する触媒となるのに適した立場にあります [1]。
ハイブリッドモデリングの詳細と、Basetwoのような企業が製造業者のモデリング技術の迅速な採用と拡大をどのように支援しているかについて詳しく知りたい場合は、Basetwoのユースケースとホワイトペーパーをご覧ください。 リソースページ。
参考文献:
- カルニアダキス、G.E.、ケブレキディス、I.G.、ルー、L. 他物理情報に基づく機械学習。ネイチャー・レヴ・フィジックス 3、422—440 (2021)
- L. フォン・ルーデン他情報に基づく機械学習 — 学習システムへの事前知識の統合に関する分類法と調査知識とデータエンジニアリングに関するIEEEトランザクション (2021)
- Lu、L.、Jin、P.、Pang、G.、Zhang、Z.、Karniadakis、G.E.、G.E.、演算子の普遍近似定理に基づいたDeepoNetによる非線形演算子の学習。ナット。マッハ。インテル 3、218—229 (2021)
- Li、Z. 他パラメトリック偏微分方程式のフーリエニューラル演算子。in Int.Conf.学ぶ。代表してください。(2021)。
- Yang, Y. & Perdikaris, P. 確率的、高次元、およびマルチフィデリティシステム用の条件付きディープサロゲートモデルコンピューティング。Mech. 64、417—434 (2019)
- Lagaris、I.E.、Likas、A.、Fotiadis、D. I. 常微分方程式と偏微分方程式を解くための人工ニューラルネットワーク。IEEE トランスニューラルネットワーク 9、987—1000 (1998)
- Mathaakis, M., Protopapas, P., Sondak, D., Di Giovanni, M. & Kaxiras, E. ニューラルネットワークに埋め込まれた物理対称性arXivでのプレプリント:https://arxiv.org/abs/1904.08991 (2019)
- Zhang、D.、Guo、L.、Karniadakis、G.E.、モーダル空間における学習:物理情報に基づいたニューラルネットワークを用いた時間依存確率的偏微分方程式の解法サイアム・ジェイ・サイエンスコンピューティング 42、A639—A665 (2020)
- 特定の高次元のハミルトン・ヤコビ偏微分方程式の粘度解を表すことができるいくつかのニューラルネットワークアーキテクチャについて、Darbon, J. & Meng, T.J. Comput。物理425、109907 (2021)。
- Raissi、M.、Perdikaris、P. & Karniadakis、G. E. 物理学に基づいたニューラルネットワーク:非線形偏微分方程式を含む順問題と逆問題を解くためのディープラーニングフレームワーク。J. Comput物理学 378、686—707 (2019)。
- Lagaris、I.E.、Likas、A.、Fotiadis、D. I. 常微分方程式と偏微分方程式を解くための人工ニューラルネットワーク。IEEE トランスニューラルネットワーク 9、987—1000 (1998)。
- Zhang、D.、Guo、L.、Karniadakis、G.E.、モーダル空間における学習:物理情報に基づいたニューラルネットワークを用いた時間依存確率的偏微分方程式の解法サイアム・ジェイ・サイエンスコンピューティング 42、A639—A665 (2020)。
- キッサス、G. 他心血管フローモデリングにおける機械学習:物理情報に基づくニューラルネットワークを用いて、非侵襲的な4DフローMRIデータから動脈血圧を予測します。コンピューティング。メソッドが適用されます。メカ。Eng. 358、112623 (2020)。
- Zhu、Y.、Zabaras、N.、Koutsourelakis、P. S.、Perdikaris、P. Perdikaris、P. 物理に制約のあるディープラーニングにより、ラベル付けされたデータを使用しない高次元のサロゲートモデリングと不確実性の定量化が可能になります。J. Comput。物理学 394、56—81 (2019)。
- Geneva, N. & Zabaras, N. による物理制約のある深い自己回帰ネットワークによる偏微分方程式システムのダイナミクスのモデル化J. Comput物理学 403、109056 (2020)。
- ウー、J.L. 他カオス力学系をモデル化するための敵対的生成ネットワークにおける統計的制約の適用J. Comput。物理学 406、109209 (2020)。
- Wang、S.、Yu、X.、Perdikaris、P. Perdikaris、P. PINNがトレーニングに失敗するタイミングと理由:ニューラル・タンジェント・カーネルの視点プレプリントは arXiv https://arxiv.org/abs/2007.14527 (2020) にあります。
- Yang、L.、Zhang、D.、Karniadakis、G.E.、Karniadakis、物理学に基づいた確率微分方程式用の生成的敵対ネットワーク。サイアム・J・サイエンスコンピューティング 42、A292—A317 (2020)。
- Pang、G.、Lu、L.、Karniadakis、G. E. FPinns:分数物理学に基づいたニューラルネットワーク。サイアム・J・サイエンスコンピューティング 41、A2603—A2626 (2019)。
- Lu、L.、Meng、X.、Mao、Z.、Karniadakis、G. E. DeepXDE: 微分方程式を解くためのディープラーニングライブラリ。サイアムリビジョン63、208—228 (2021)。
- Wang、S.、Teng、Y.、Perdikaris、P.、物理情報に基づいたニューラルネットワークにおける勾配病変の理解と軽減。arXiv https://arxiv.org/ abs/2001.04536 (2020) でプレプリント。


